最近结束了在360公司的大模型算法的实习,想要记录下实习的经历和一些想法,本篇博客的基本内容如下:
- 面试经历
- 主要工作内容
- 实习体验与个人收获
面试经历
拿到360的大模型算法实习是一个非常意外的事情。去年十一月份的时候,我在boss直聘上收到了360HR的面试邀请。自己当时处在一个挺迷茫的阶段,手头上有一个单细胞数据分析的课题,但是进展并不顺利,不知道怎样从数据中分析出有用的信号。单细胞数据分析这边课题组也并没有相应的经验积累,基本就是自己一个人在不断试错,整个人的情绪就是迷茫、烦躁、颓废。收到面试邀约后,想了想感觉大模型算法是个挺炫酷的事情,360也算是不错的公司,如果能去实习一下,在公司里做点有及时反馈的东西总比自己一个人死磕这个课题强,所以决定面一下试试。
说实话,面试前我对拿到这个offer并没有太大期望,因为转博考试之前自己也投递过一些实习,想着万一硕士毕业就直接工作好了,上半年的实习投递彻彻底底打碎了我的一些幻想,没有深度学习经验的数学系学生基本上是没有机会拿到互联网公司的算法实习的,运筹算法可能稍好一点,但相应的名额也是非常少。而我当时的背景就是一个基本不懂深度学习的数学系学生…
自己当时的简历基本情况如下:
- 数学所运筹专业硕博连读学生
- 有一篇在投论文,但是主要工作都是生物合作者的,我只是拿朴素贝叶斯模型帮他们编了一个小的故事。
- 几个野鸡算法比赛的3%左右的排名,(虽然野鸡但也是一个相对完整的project,至少我觉得比我那篇在投论文更像一个运筹专业的project),一个是基于遗传算法的车间调度,一个是基于GBDT的生物样本预测。
- 一家初创公司,玻色量子的实习经历,公司是做量子计算的,自己在里面做的主要是业务相关的运筹算法。
- 唯一的深度学习经历是两个课程,cs224n(nlp课程)和cs224w(图神经网络课程),自己做完了课程作业并看了一点相关的论文。
- leetcode,除了一点点动归别的啥也不懂
Anyway就这么个背景,抱着面过了我赚了,面不过我不亏的信念开启了第一次面试。一面面试官也是我后来实习的导师——赵光香老师。光香老师是非常棒的导师,这份实习和他合作,从他那边学到了很多做研究的想法。面试开始是常规的自我介绍、项目介绍,接下来就是神奇的唠嗑环节,大概也是因为我没啥nlp相关经验,问八股不如唠闲嗑。唠嗑一会儿后让我读一篇论文并解读论文的主要思想,这个环节我应该做的还不错,数学系的不写代码讲几个公式问题还是不大。最后做了一个leetcode,在光香老师的两次提示下总算是过去了。
以上是一面的流水账,二面是团队的领导面,二面的项目主要问的是之前的实习,之前实习中做的是用ADMM(交替方向乘子法)去优化公司的量子算法模拟器求解算法。当时领导可能还觉得我能试着去改进下LLM的优化啥的,毕竟ADMM听起来还是挺唬人的…总之二面也顺利过去了,最后在十二月份的时候结束了HR面,正式开始自己的大模型算法实习。
主要工作内容
在360的实习中,我所在的团队是360智脑大模型的预训练团队,整个团队的主要工作是尝试不同的“数据-模型—训练方式”的组合去提升模型效果。我做的是偏向于数据的工作,针对特定的领域知识进行包括数据清洗、数据合成的方式增强数据质量,进而提升模型性能。
刚开始实习时,光香老师有让我尝试微软的Phi模型的技术路线,即通过大模型去生成教科书数据,改善模型训练效果。后来我改做从360内部的文库数据中,清洗或者合成高质量的推理数据,增强模型的推理能力。下面是我的主要工作内容:
文库数据重做
- 文库数据中试题内容抽取
- 基于文库数据中缺失数学试题的重构
- 数学相关数据训练、评测
试题内容抽取
试题数据过滤:
利用关键词筛选试卷相关文档,试卷关键词有 [‘试题’,’试卷’,’月考’,’期中’,’期末’,’中考’,’高考’]。
试题数据拆分:
文库数据中,试题解析较混乱,尤其是数学试题中各种符号缺失和解析错误,难以通过正则将试题实现精准的拆分。解决思路是先通过正则进行粗略拆分,之后使用分类器从中筛选有效的试题语句。
正则拆分规则:
parts = re.split('(\d+、)', sheet) # 使用题号拆分 1、 2、 3、 这样的题目序号作为分隔符
分类器筛选:
对前面的拆分试题进行注释,人工标注1k条拆分的试题片段,微调一个Bert分类器用于筛选。
基于文库中缺失数学试题的数据增强
前期的试题内容抽取存在一个问题,由于数学试题的解析错误,过滤后的试题几乎不包括数学相关题目,为了充分利用文库中的数学内容,增强模型推理能力,选择对试题进行分类,之后对数学试题进行拆分及重做。
试题数据分类:
关键词分类,根据 “语文” “数学” “英语” “物理” “化学” “生物” “政治” “地理” “其他” 将试题分类为不同学科
数学试题重做
将数学试题通过正则拆分,之后将每条潜在的数学数据送入大模型进行重构。即让大模型自行判断试题是否包含有效的数学内容,如果包含,尝试重构这道试题和相应解析。
正则拆分规则:
parts = re.split('(\d+.)', sheet) # 使用题号拆分 1. 2. 3. 这样的题目序号作为分隔符
prompt尝试:
试题重做的prompt是个很关键的点,我在工作中发现,基于知识点总结的试题重做效果要显著优于直接重做。下面是具体的说明:
-
直接要求大模型根据缺失试题生成一道高质量的带解析的数学题目。测试了qwen, gpt-4, claude 等模型,都无法从缺失较多的数学题目中高效重建试题。即使使用few shot提示,也没有明显改善
-
在prompt中增添关键词“从缺失的题目中总结知识点,并根据总结的知识点生成一道相关的数学试题”,使用“知识点”提示后,模型的生成效果显著增强。下面是示例的prompt,该prompt对qwen-72b, gpt-4都有效,但在qwen14b,qwen7b上会产生大量无关的文本信息。
你将阅读一段内容有严重缺失的与数学相关的试题片段,你需要首先判断该片段是否包含数学试题内容,若不包含,直接输出“无效内容”,若包含数学试题内容,你需要首先从中提取相关的数学知识点,之后根据提取的数学知识点,结合试题内容,生成一道相关的数学题目,最后为你生成的题目推导答案并提供解析,你需要一步步的推理,给出每步推理的理由,下面时你要阅读的试题内容:{content}请注意,这些试题片段存在严重的缺失,你可以以超过百分之五十的概率选择输出“无效内容”,你只需要处理你高度确信的数学试题。
- 参考MAmooTH的工作,在prompt中增添POT的要求,使用“总结知识点+COT+POT”的prompt增强数学试题,下面是qwen72b的prompt。
你是一个经验丰富的数学教师,你将阅读一段存在内容缺失的数学试题,按照如下步骤对试题进行处理。首先判断该片段是否包含数学试题内容,若不包含,直接输出“error”。若包含数学试题内容,首先总结相关的知识点,之后根据知识点生成一道相关的数学题目,最后为生成的题目推导答案并记录推理过程。你要一步一步的思考问题,详细的给出每步推理的理由。为了提高推理的准确性,你要使用逻辑推理和程序推理两种方法生成结果。逻辑推理是通过数学定理、数学知识进行推理。程序推理是指尝试编写一个python程序求解这个问题。最终按照 题目,知识点,逻辑推理,程序推理的顺序生成结果。下面是你要阅读的试题内容:{} 注意,这些试题片段存在严重缺失,为了尽可能保证生成题目的有效性,你只需要处理高度确信的数学试题,生成的试题只需要在知识点上密切相关,内容上可以与阅读的试题不一致。严格按照要求的格式输出markdown类型的文本。
数据生成结果:
| 模型 | prompt格式 | 用时-成本 | 存储 |
|---|---|---|---|
| qwen72b | COT | 单机8$\times$A100,96h | 432M, 570K条数据 |
| gpt-4 | COT | 18h,花费2.4万 | 81.7M, 79K条数据 |
| qwen-72b | COT | 4机32$\times$A100,110h | 723M, 1.18M条数据 |
| qwen-72b | COT+POT | 单机8$\times$A100, 90h | 226M, 154K条数据 |
| gpt-4 | COT+POT | 32h, 花费2.4万 | 英文数据 |
以上数据除最后的gpt-4数据外,都是中文数学试题数据。
生成数据训练
使用qwen14b模型进行二阶段训练,训练5b数据。评测结果表明,使用gpt-4合成的COT数据能够提升模型的数学推理能力,在MATH数据上有明显的提升。qwen72b合成的数据尚未进行二阶段训练。
使用LLaMA-Factory基于LLaMA2-7b进行SFT,快速评估数据集效果,SFT实验表明,gpt-4重做的COT数据在MATH数据上同样有提升。
数学评测
数学的评测使用opencompass实现,在实习中,注意到opencompass内部的数学结果解析存在一些问题并进行了修改。
opencompass的math评测存在解析问题:
- latex 中多重大括号,例如
输出:\frac35
答案:\frac{3}{5}
- 答案中无效的text,例如
输出: \text{M}
答案: M
小结
以上是个人在360的主要工作内容。自己还是比较满意的,毕竟在兼顾组内科研的情况下,半年的时间从一个NLP小白到基本了解大模型训练流程并参与其中,follow相关的研究成果并做出了一点自己的尝试(基于关键点的数学试题增强,和MSRA的一个工作撞了idea哈哈哈)。虽然最后并未以论文的形式产出成果,但是过程中还是学到了很多。
后面我用qwen生成的数据也做了完整的继续预训练,相关的评测结果如下
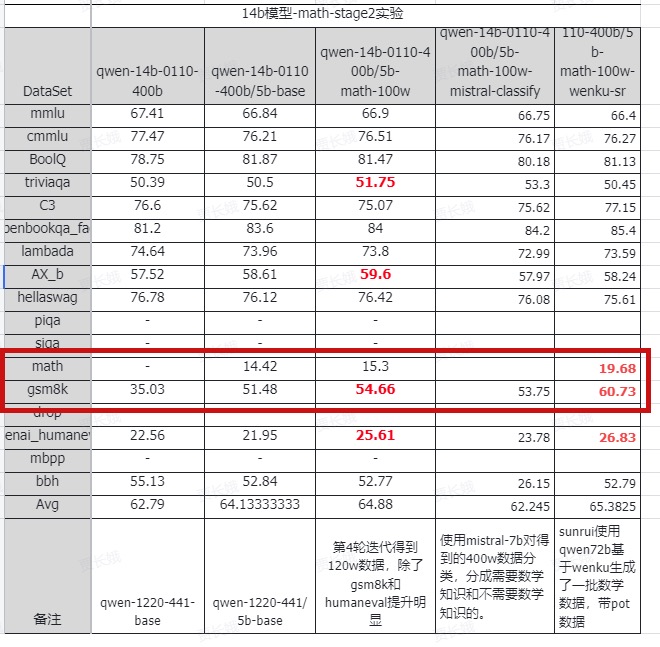
其中最后一列是加入我的qwen72b数据训练后模型的提升,可以看到在框出的math和gsm8k这两个指标上,14b模型的得分有了显著的提升,nice!!!
这里也一定程度上驳倒了光香老师的qwen无用论哈哈哈,合适的prompt加足够多的试题量,qwen生成的数学数据是可以发挥作用的。
实习体验与个人收获
实习体验
非常满意的一份实习。光香是非常包容的老师,对我这样的nlp小白,加入公司后两三个月都在摸索学习nlp、llm相关的一些基础知识没有什么实质性的工作产出,依然很有耐心的和我讨论问题。同时整个团队的氛围也很好,工作上的问题都能很快得到同事们的支持。当然也感受了一波互联网公司的氛围,确实是强度很大,比数学院轻松的养老氛围要卷很多,让我开始思考以后尝试一下跨国药企的生信研究岗位了。
个人收获
技术上的话,做了llm、nlp方向的一些技术实践,比如自己搞一个transformer,继续预训练,微调Bert、LLaMA,大模型评测等等。后面在科研中,应该不会再对搞神经网络打怵了。
职业发展的话,体验了互联网公司的氛围,开始考虑是否要强行进入这样一个高薪高强度但是和自己不是百分百匹配的行业。不是完全对口意味着自己读博期间要付出额外的努力去学习这个岗位的知识,积累项目经验或者实习经历。同时还要和对口专业的同学去竞争,进入岗位后一段时间肯定还是积累学习的过程,不太可能主导一个项目。而如果后面选择生信相关的工作,可能收入上会低一些,但是能更好的发挥自己的研究专长,主导项目的概率会更大。所以后面打算在科研上再努力一把,工作时尝试一下跨国药企的生信研究岗位。
还有一些工作交流上的反思。开始实习时,自己对大模型是纯小白的状态,工作中遇到的问题多去请教同事,而不是执着于自己解决,应该会更快的推进项目。自己在这一块做的并不好,交流沟通更积极一些的话,也许离职的时候就能把论文做完了哈哈。
最后一点是研究上的收获,这一点光香老师教了我很多,他经常找我聊一些idea或者让我讲一些idea。感觉做AI研究者的思路和数学研究者的思路是有挺大差异的,很多AI研究者的idea看起来更小更具体一点,而导师这边则倾向于讲一个更大更完整的故事。但是AI研究的有一点是很好的,那就是有Idea就赶紧做出来,做出来再看有什么问题,搞数学的在建模前就会考虑一些有的没的的问题,所以做工作就会慢不少。后面打算借鉴AI的思路去把毕业论文工作抓紧整出来,就两点:
- 不要嫌弃想法太小,有了就赶紧做
- 先做出来在完善,不要还没做就想方方面面都考虑到。
总之,收获满满的一份实习。再次感谢光香老师,愿意给我这个小白一张大模型的船票。