这篇blog主要记录如下内容:
- 自己的单细胞预训练模型尝试。
- 自己的bert-base和gpt2预训练尝试。
单细胞预训练模型尝试
这段时间主要尝试了如下工作:
- Transformer-based scRNA-seq pretrain
- Multi-omic pretrain
- scATAC-seq pretrain
Transformer-based scRNA-seq pretrain
对transformer-based scRNA-seq pretrain工作,尽管当前有相当多的scRNA-seq 预训练模型是基于这个框架的,但我本人依旧持怀疑态度。我不认为scRNA-seq这种表格数据适用于Transformer based model。原因如下:
- 无明显效果提升。数据竞赛中有相当多的表格数据比赛,但就我个人经验来看,将特征强行使用embedding升维的transformer-based model并没有展现出显著超越GBDT或者简单的MLP模型的效果,21年的研究也有分析这一点(Revisiting Deep Learning Models for Tabular Data)。同时,一些针对单细胞预训练模型的评测也表明这些模型并没有bert、gpt之于NLP那样的显著提升。
- Transformer模型的优势未充分利用。在我看来,Transformer-based model首先是序列模型,其最显著的优势是相比RNN可以进行高效并行以及增强了相隔很远的token之间的关联。但是scRNA-seq是高维表格数据,MLP就可以实现全局特征之间的交互,使用transformer捕捉全局交互的必要性不大。同时转成序列后必然要面临高维问题,语言的建模也许只需要几百个token就足够实现不错的效果,但是几百个gene对于刻画一个细胞来讲是丢弃了太多信息的,这样一来无疑增大了训练的难度。可以看到,所有的Transformed-based scRNA-seq model 最多只训练到4k个gene的长度,并且这需要相当的计算资源。而scvi这种MLP-based模型训练4k个gene,在本地的cpu上都能很快实现。两相对比,这种训练难度的增加,是否是“没苦硬吃”?
在以上怀疑态度下,依旧尝试训练一个的Transformed based scRNA-seq model的动机是,我对这种transformer-based model的训练过程好奇,怎样实现这个工程,怎样处理数据集,怎样搭建模型和训练脚本,怎样评测……训练过程中loss会怎样变化,能否有有效的loss下降(先前有评测发现一些单细胞大模型即使在pretrain loss上,都没有很好的实现Loss下降). 以上问题,自己试一试就好了。
这个项目的地址在github,目前是第一版草稿,后续优化过的版本会更新上去。下面简单说下项目细节。
数据
使用的Allen脑科学研究所2021、2024年发布的两个小鼠全脑scRNA-seq数据,大约4M个细胞。
训练任务
基因表达预测
将细胞表达数据转化为 表达token + gene id的形式,即
gene_id = [gene_0, gene_1, gene_2, ..., gene_n]
exp_token = [count_0, count_1, count_2, ..., count_n]
cell_embed = (gene_0_embed + count_0_embed, ..., gene_n_embed + count_n_embed)
mask 掉一些count数据,预测count。
gene_id = [gene_0, gene_1, gene_2, ..., gene_n]
exp_token = [count_0, mask, count_2, ..., count_n]
cell_embed = (gene_0_embed + count_0_embed, gene_1_embed + mask_embed..., gene_n_embed + count_n_embed)
对比学习
对每个cell, 通过抽样的方式得到一个细胞的两个随机子集,要求两个基因集合下得到的cell embedding 相似。使用Clip loss进行对比学习。
模型架构
类似于bert类型的encoder-only架构,训练loss有两个,一个是count预测loss,一个是对比学习loss。count预测loss这里直接用了cross entoropy loss( ce loss不合理, 因为基因表达量是一个存在序关系的物理指,直接做成分类肯定有问题,但是后面训练一点学不到更不合理)。
训练细节
count embed vocab size: 100 (大于100表达全部截断)
mask ratio: 0.1
seq len: 1000
d_model: 256
n_head: 8
d_ffn: 1024
n_layer: 4
batch_size: 16 (事实上是32,因为每个cell 都有两个抽样)
gradient_accumulation_steps: 8 (因此每个batch相当于 32*8=256)
training_steps: 20000 (训练了大约5.1M个cell)
lr: 1000步 warmup 到 1e-3, 之后10000步cosine退火到5e-4, 最后保持5e-4
clip_loss_weight: 0 (主要是check一个评测论文观点,恢复基因表达这个任务能否有效训练,因此关掉对比loss)
使用单张A6000 48GB 显卡进行训练,手搓的代码效率一般,看GPU利用率刚过半,但是显存已经占满了。
训练结果
令人心碎的结果。已知count的vocab_size数目是100,随机预测的loss也应该是np.log(100) = 4.6052。结果训出来发现,5000步就不下降了,同时连随机预测效果都不如……
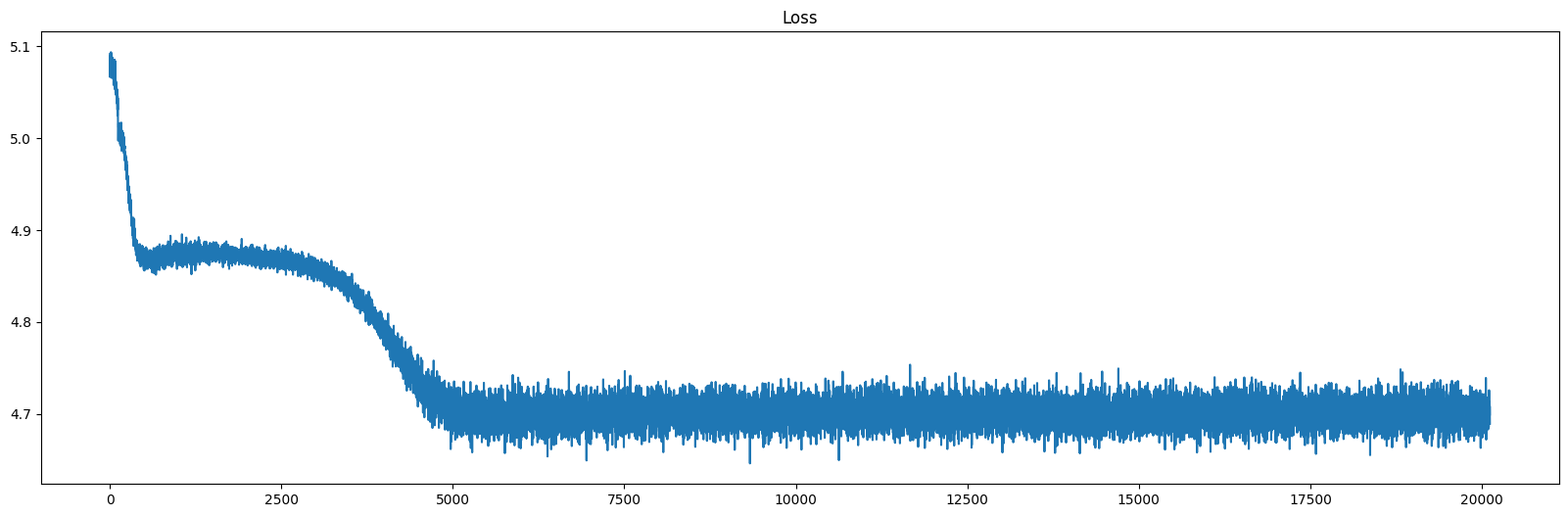
对上述模型,并未进行后续的评测,例如cell embedding的效果,这个pretrain loss 就够绝望了。
训练失败的原因,猜测如下几点:
- ce_loss 使用
- lr 不合理,后面自己尝试bert pretrain的时候发现lr 峰值设置为2.5e-4,最后会逐步降到0, 或许设置的lr太大了。
- 模型大小偏小。1K的序列长度,但是很小的transformer 层数和dim_model, 不足以学习到这些信息。
后续也许会重新尝试训练。
snATAC-seq pretrain
RNA-seq的预训练有很多,但是ATAC-seq的预训练几乎没有,所以想尝试下。
ATAC-seq预训练工作较少的原因,猜测:
- ATAC-seq数据少,cellXgene项目收集了大量的scRNA-seq数据,但是scATAC-seq数据缺少类似项目。
- ATAC-seq数据质量较RNA-seq要差一些,研究可能优先关注RNA-seq。
- ATAC-seq数据特征不统一,需要额外的call peak或者peak merge环节。
- 高维。比起scRNA-seq数据,ATAC的维度更高,通常在10万维往上,这时一个简单的MLP可能都会带来几百万的参数量。
对ATAC-seq数据的预训练,我使用的数据是23年任兵课题组发布的小鼠脑区ATAC-seq数据,总计2.3M个细胞。特征按照基因组分bin,共5.5M个特征。
我的预训练策略参考了Wav2vec2,使用CNN实现快速降维,之后用Transformer捕捉全局信息,同时VQ-VAE和transformer之间的表示进行对比学习实现自监督训练。
结果并不成功。预训练loss中,对比学习loss几乎没有下降。后续的cell embedding相关的评估也没有进行。
训练失败的原因,猜测如下几点:
- atac_seq数据和音频数据之间的差异,atac_seq数据高度稀疏。
- 不合适的lr设置
mulit-omics pretrain
多组学数据数据量较少,可能达不到通常的pretrain需要的数目。但是考虑到其提供的多模态信息,还是值得尝试。
多模态的核心是跨模态整合,目前在小数据集上取得了不错的效果,还在推进中。
语言模型预训练demo
前面的单细胞预训练模型的失败让我想要尝试复现一些初级的语言模型预训练工作,了解数据集的构建、训练参数的设置以及loss曲线的下降等信息。 借助一块A800显卡和transformers库,我尝试了RoBERT、GPT2-base的预训练。
参考资料
Roberta和GPT2-base的预训练主要参考了如下资料参考链接
数据集
预训练数据集使用的是数据链接。主要是一些 通用文本数据,共计80M条数据,14.4GB。
数据集处理流程及模型训练
- tokenization。借助分词器,将文本数据分词,得到token id 序列。
# GPT2 分词示例
# load the gpt-2 tokenizer
tokenizer = AutoTokenizer.from_pretrained("../hf_model/gpt2")
tokenizer.pad_token=tokenizer.eos_token
# tokenize
def tokenize_function(example):
#return tokenizer(text=example["text"]) # warning for seq-length larger than tokenizer.model_max_length ## 这里可以不需要截断的,后面的chunk函数会将文本拼接后分割成1024的输入长度
return tokenizer(text=example['text'], truncation=True, max_length=tokenizer.model_max_length)
tokenized_ds = dataset.map(tokenize_function,batched=True,remove_columns='text', num_proc=num_proc)
# save to disk if required (use load_from_disk latter)
tokenized_ds.save_to_disk('../hf_data/gpt2tokenized_bert_pretrain')
- chunk。将文本数据拼接并截断成等长的序列,构成输入的batch。
# Make samples to a size of 1024
def concat(examples):
examples["input_ids"]=[list(chain.from_iterable(examples['input_ids']))] # convert chain to list of tokens
examples["attention_mask"]=[list(chain.from_iterable(examples['attention_mask']))] # convert chain to list of tokens
return examples
# takes a lot of time (worth saving it to disk)
concated_ds = tokenized_ds.map(concat,batched=True,batch_size=1000000,num_proc=256)
def chunk(examples):
chunk_size = 1024 # modify this accordingly
input_ids = examples["input_ids"][0] # List[List], pass the inner list
attention_mask = examples["attention_mask"][0] # List[List]
input_ids_truncated = []
attention_mask_truncated = []
#slice with step_size=chunk_size
for i in range(0,len(input_ids),chunk_size):
chunk = input_ids[i:i+chunk_size]
if len(chunk)==chunk_size: # drop the last chunk if not equal
input_ids_truncated.append(chunk)
attention_mask_truncated.append(attention_mask[i:i+chunk_size])
examples['input_ids']=input_ids_truncated
examples["attention_mask"]=attention_mask_truncated
return examples
chunked_ds = concated_ds.map(chunk,batched=True,batch_size=2,num_proc=256)
chunked_ds.save_to_disk('../hf_data/gpt2tokenized_bert_pretrain_chunked_ds') # will use this latter for diff experimentation
- Dataloader
data_collator = DataCollatorForLanguageModeling(tokenizer,mlm=False)
- 加载模型并设置训练参数。需要注意的是per_device_train_batch_size 和 gradient_accumulation_steps 这两个参数。为了在有限的显存下增大batch size,使用梯度累积的策略来增大batch size。实际的batch size 是这两个参数的乘积。
# load the model
configuration = GPT2Config()
model =GPT2LMHeadModel(configuration)
# training arguments
training_args = TrainingArguments( output_dir='gpt-2-warm-up/standard-gpt',
eval_strategy="steps",
eval_steps=10,
num_train_epochs=1,
per_device_train_batch_size=32,
gradient_accumulation_steps=16,
per_device_eval_batch_size=16,
learning_rate=2.5e-4,
lr_scheduler_type='cosine',
warmup_ratio=0.05,
adam_beta1=0.9,
adam_beta2=0.999,
weight_decay=0.01,
logging_dir='./logs',
logging_strategy="steps",
logging_steps = 10,
save_steps=1000,
save_total_limit=10,
report_to='tensorboard'#'wandb',
)
trainer = Trainer(model=model,
args = training_args,
tokenizer=tokenizer,
train_dataset=chunked_ds["train"],
eval_dataset=chunked_ds["test"],
data_collator = data_collator)
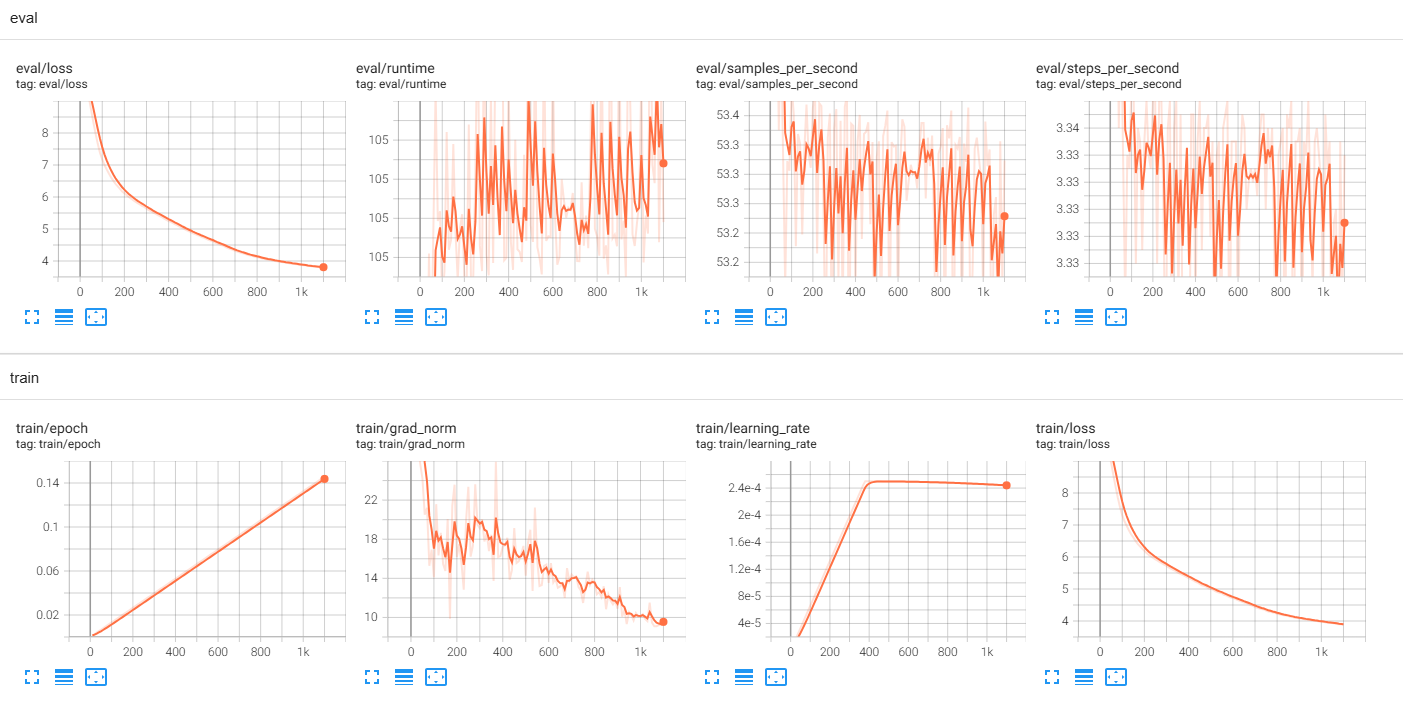
训练结果
GPT2训练了1.1K后意外中断,但是还是能够看到loss 的下降趋势以及一个能说点胡话的GPT。
prompts = 'A long time ago, there is a boy called Super Rui' #"I was telling her that"
inputs = tokenizer(prompts,return_tensors='pt').input_ids
outputs = model.generate(inputs, max_new_tokens=100, do_sample=True, top_k=10, top_p=0.95)
res = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(res)
A long time ago, there is a boy called Super Rui. He was a good man to be killed in a coma.
In the summer of 1925, the young man was taken prisoner to a prison and found a few days earlier.
After the murder, the young man was shot to death in a suicide trial, a suicide sentence was
found guilty of the murder, and a few were killed. The murder was released in a prison prison
in June 1921, and his wife died.The murder, the police was killed and the police arrived to
Bert 完整训练了一个epoch,花了大概5天的时间
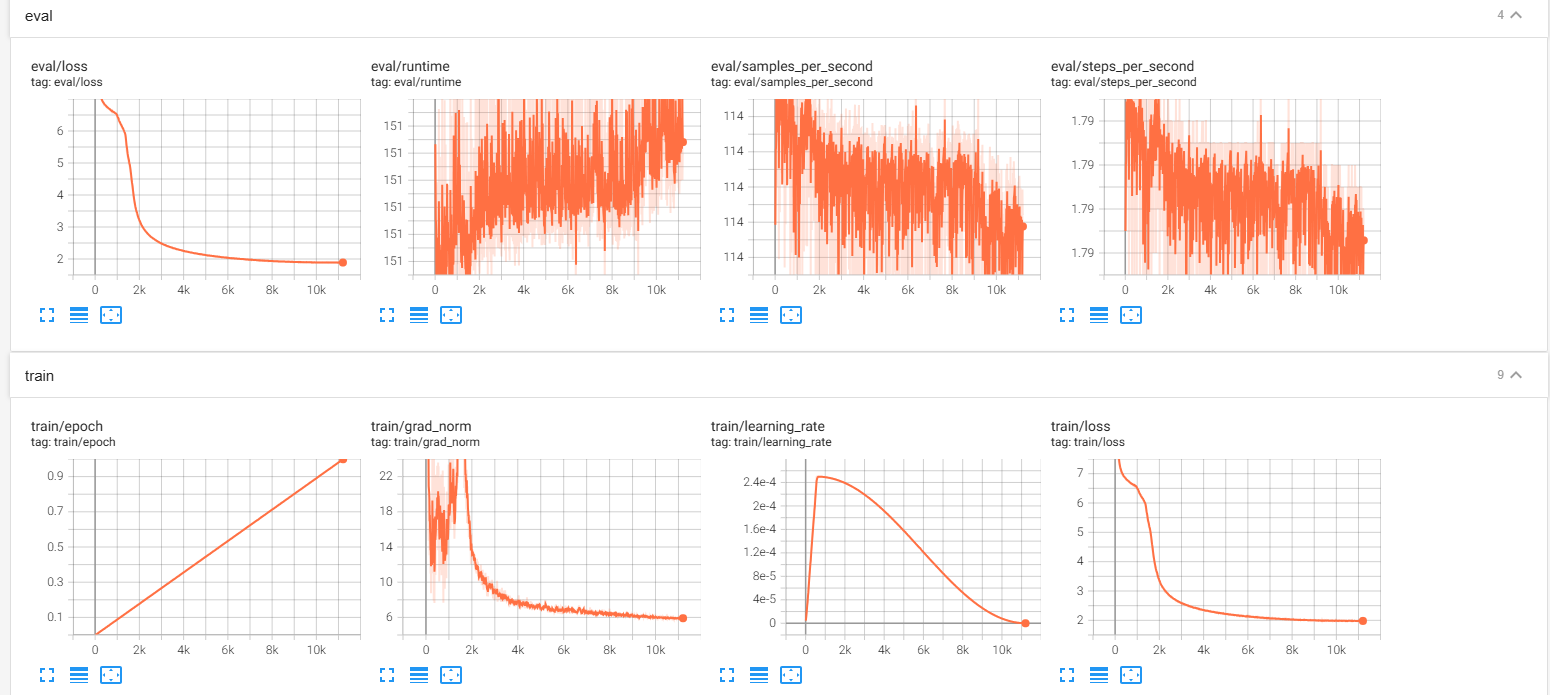
虽然这个bert的训练Loss看起来很不错,但得到的bert在常识性问题上表现很垃圾,例如下面这个巴黎是法国的首都的填补就在胡说八道
sentence = "Paris is the capital of <mask>."
inputs = tokenizer(sentence, return_tensors='pt')
outputs = model(**inputs)
# 获取预测的概率分布
predictions = outputs.logits
# 找到 mask 位置
mask_index = (inputs.input_ids == tokenizer.mask_token_id).nonzero(as_tuple=True)[1]
# 获取 mask 位置的预测分布
predicted_distribution = predictions[0, mask_index].softmax(dim=1) # 使用 softmax 转换为概率
# 获取概率最高的前十个 token ID 及其概率
top_k_values, top_k_indices = predicted_distribution.topk(10)
# 解码这些 token 并打印结果
for value, index in zip(top_k_values, top_k_indices):
K = len(index)
for i in range(K):
idx = int(index[i].item())
word = tokenizer.decode([idx]) # 将索引转换为单词
probability = value[i].item()
print(f"Word: {word}, Probability: {probability:.4f}")
Word: me, Probability: 0.0416
Word: you, Probability: 0.0397
Word: hell, Probability: 0.0251
Word: him, Probability: 0.0228
Word: us, Probability: 0.0228
Word: earth, Probability: 0.0191
Word: town, Probability: 0.0185
Word: her, Probability: 0.0161
Word: them, Probability: 0.0153
Word: yours, Probability: 0.015
这是因为训练数据中根本没有涵盖这种常识性内容,挑一个训练数据中的语句就会表现很好。这里进一步强调了数据在语言模型预训练中的重要性。数据质量、数据多样性、数据量直接决定了模型的性能。在数据上花时间是值得的。这次尝试也让我更加认识到当初在360的那份实习中做数据的重要性。
小结
主要收获就是三点:
- llm模型训练过程中的loss变化,我的两个单细胞模型的loss变化基本上就宣布了模型的失败,不太可能出现这样的训练曲线。
- 预训练模型的数据集直接决定模型的性能。
- 预训练任务中,构建数据集、准备训练脚本的基本流程。